Продуцент программного обеспечения:
Convera Technologies International Ltd
Продукты, с которыми может взаимодействовать программноеобеспечение
RetrievalWare:
RetrievalWare
является системой, служащей для поиска ресурсов электронной
информации огромного объёма из различных источников
Основная информация
RetrievalWare
является безопасной, градуированной, в широком смысле,
платформой, для реализации аппликаций, связанных с поиском и
определением категории информации. Разрозненная архитектура
RetrievalWare,
созданная на базе проверенной, производительной технологии,
представляет высопроизводительную инфраструктуру для
индексирования, поиска, определения категории и соединения
информации огромного объёма из различных источников.
Огромное количество данных хранится в неструктурной форме, чаще
всего, в виде написанных разговорным языком, текстов. Богатство
этого языка приводит к тому, что идентичная информация может
быть записана разным способом. Давайте представим, что хотим
найти документы, касающиеся автомобилей. Вероятно, мы будем
заинтересованы также документами, в которых появятся слова:
авто, воз, бричка... В традиционном подходе, поиск заключается
на проверке появления в документе определённого слова. В
это же время, при поиске информации, мы часто бываем больше
заинтересованы понятием, которое может быть выражено
простонародным языком по-разному.
Другой проблемой, связанной с добыванием информации из текстов,
написанных простонародным языком, является изменение слов. В
традиционном поиске слов, выбор слов, является заданием
пользователя. Упущение какой-либо формы слова, может обозначать,
что не будет найден существенный – с точки зрения поиска
информации – документ. Всё усложняется существованием разных, но
правильных языковых форм.
Не менее существенной проблемой является правильная запись
текста. Проблемы с орфографией и грамматикой приводят к тому,
что информация, которую мы ищем, бывает записана в неожиданной
для нас форме.
Задание поиска документов об автомобилях, которое вначале
выглядело простым, увеличилось до:
-
Нахождение слов, представляющих в просторечии разыскиваемые
понятия вместе с однозначными словами;
-
Создание списка грамматических форм для всех разыскиваемых слов;
-
Создание списка ошибочных записей для данной формы, которые
теоретически появятся в текстах.
Такой подход обеспечивает комплектный поиск: в результате поиска
мы можем ожидать всего или почти всего количества документов,
касающихся информации, которую мы разыскиваем.
Конечно же, высокая коплектность ведёт к снижению точности
поиска: в результате поиска мы можем ожидать большого
количества документов, которые, хотя и содержат слова из
созданного нами списка, не являются существенными для нас. (В
примере с автомобилями, одним из разыскиваемых слов, является
воз. В результате могут появиться документы, в которых
будет содержаться, напр., Большой Воз, что не относится к
интересующей нас теме).
Для того, чтобы иметь такие результаты в традиционных системах
поиска, пользователь создаёт список синонимов, формы изменения
слов, возможные ошибки, а впоследствие производит отсев
несущественных документов. А на подлинный анализ информации,
часто уже не остаётся времени.
Очень существенным вопросом для сохранения высокой комплектности
при большой точности оиска, является более широкий анализ текста
документа. Следует принять во внимание не только факт, что
данное слово появилось в документе, но и количественную оценку
появления этого слова, его синонимов и других слов из этой
области. Благодаря такому углублённому анализу,
можно
систематизировать документы таким образом, чтобы наиболее
существенные из них, для нашего поиска, стояли в начале
ранкинга.
Источники информации, которые мы бы хотели принять во внимание,
могут быть очень разнообразными. Ресурсы, которые находятся в
системе файлов фирмы, в самых различных формах, системы
управления документами, системы групповой работы, базы данных,
бизнес-аппликации и, наконец, ресурсы
WWW
– всё это потенциальные источники, существенной для нас
информации. Важнейшая проблема с такими многообразными
источниками состоит в том, что не хватает инфраструктуры, на единое отношение к ним. Мы часто вынуждены отдельно выискивать
каждый
из этих источников, а затем соединять результаты поиска,
чтобы получить полный образ информации на заданную тему.
С разнообразием источников информации тесно связан вопрос
безопасности – пользователь, который ищет информацию, должен
иметь гарантированный доступ к тем информациям, на которые
имеет правомочия.
Система
RetrievalWare
составляет превосходную платформу решения всех представленных
выше проблем.
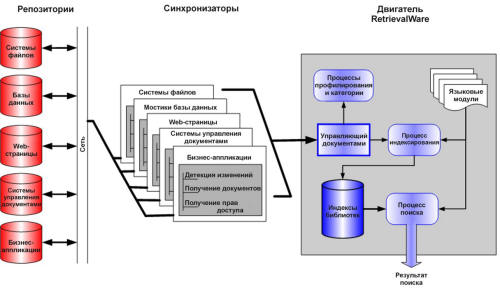
Репозиторий и доступ к данным
Безопасный и расширенный доступ к репозиторию
RetrievalWare,
контролируется синхронизаторами фирмы
Convera,
которые обслуживают более 200 типов документов на серверах
файлов в системах групповой работы, таких, как
Lotus Notes
и
MS Exchange,
в реляционных базах данных (MS
SQL,
Oracle,
Sybase,
Informix,
Teradata),
в системах управления документами (Stellent,
Dokmtum
и
FileNET)
в пространстве страниц
www.
Синхронизаторы автоматически выкрывают изменения, модификации и
актуализации информационных ресурсов в целой системе и
автоматически актуализируют индексы, чтобы результаты поиска
совпадали с актуальным состоянием репозитория информации. Если
системе требуется доступ к репозиторию или типу файла, который
не обслуживается синхронизаторами, можно создать нужные
синхронизаторы при помощи
AFM Toolkit,
являющиеся частью
RetrivalWare Developer Extensions SDK.
Поиск и квалификация
Главной целью поиска информации в системе
RetrievalWare,
является гарантия комплектного поиска с сохранением высокой
точности. Три метода поиска – понятийный, поик образцов и метод
Буля, которые могут использоваться независимо или вместе, что
позволяет пользователю выбрать гибкий метод поиска для своих
потребностей. Точность поиска и порядок обратных результатов
увеличивает уникальную технологию классификации и категорий.
Благодаря такому подходу
RetrievalWare
достигает исключительную точность и комплектный поиск.
Поиск понятийный (анг.
Concept search)
В этом методе поиска оригинальные термины (звенья) вопроса
дополняются словами, связанными с ними. Дефиниция лексических
связей в понятиях происходит с использованием семантической
сети. Фирма
ACSYS BSC Sp.
z o.o.,
единственная на рынке предлагает возможность использования
семантического польского языка с объёмом 80 000 слов в методе
поиска понятийного. Это решение вместе с уникальной системой
флексии польского языка (обслуживающей больше 1,7 млн словарных
форм) даёт абсолютный комплектный поиск знаний в документах,
независимо от способа их описания.
Поиск образцов (Pattern
search)
Написание слов может существенно отличаться из-за
орфографических ошибок в оригинальных документах или из-за
позднейших ошибок введения данных, которые могут возникнуть в
процессе
OSR
или ручного введения данных. Оригинальное решение
APRP™(англ.Adaptive
Pattern recognition Processing)
позволяет найти слова, введённые с ошибками в тексте документа,
основываясь на подобии слов для поданного текстового образца.
Поиск методом Буля (англ.
Boolean
search)
RetrievalWare
обеспечивает также поиск методом Буля, который называется также
поиском ключевых слов Пользователь может создавать сложные
условия, логично пользуясь операторами поиска Буля.
Постоянная и динамичная классификация
Продвинутое решение Динамичной Категории и Классификации
RetrievalWare
позволяет открыть связь между разнородными источниками
информации. Пользователь может начать поиск и автоматически
классифицировать результаты поиска согласно с ранее определённой
или созданной динамично классификацией. Являясь основой
классификации, таксономии могут быть таксономиями
предоставленными вместе с
RetrivalWare
или таксономиями, предназначенными для данного клиента.
Благодаря применению этих классификаций, пользователи получают
возможность систематического упорядочения результатов, согласно
с всеобщими принятыми научными критериями.
Интеллигентный ранкинг документов
RetrievalWare
оборудован технологией интеллигентного ранкинга документов.
Каждый документ имеет свою правильность по отношению к
поставленным условиям. Правильность документа высчитывается на
основе количества выступающих слов, которые связаны семантически
со словами вопроса, степени близости значения, а также степени
распространения найденных слов в документе.
)